API接口逆向思路 - 拼多多篇
前段时间有个客户找我做一个和拼多多相关的业务,重点询问了我一个有关拼多多接口的问题,我因为比较忙,所以没帮他写,但是提供了一个思路给他,接下来我们一起看看这个问题。
做过拼多多接口逆向或者其他平台(比如德州仪器,耐克)逆向的同学,可能对 API 的校验非常了解,常规 API 除了最容易获得的 Token 以外,Request Header 中还会附加一些其他的自定义内容用来加强保护 API 强度,比如最出名的是 Akamai 公司的 Sensor_data, 这个 request 属性中包含的内容堪称变态,大概有鼠标轨迹,浏览器指纹,canvas 指纹,SSL 指纹,时间戳算法,键盘动作等等,能逆向成功并且通过 Akamai 检测的同学可以说已经是行业顶级了。那接下来我们一起看看拼多多的防范手段。
我们随便进入一个拼多多的页面,然后查看开发者工具你会看到这样一个东西。
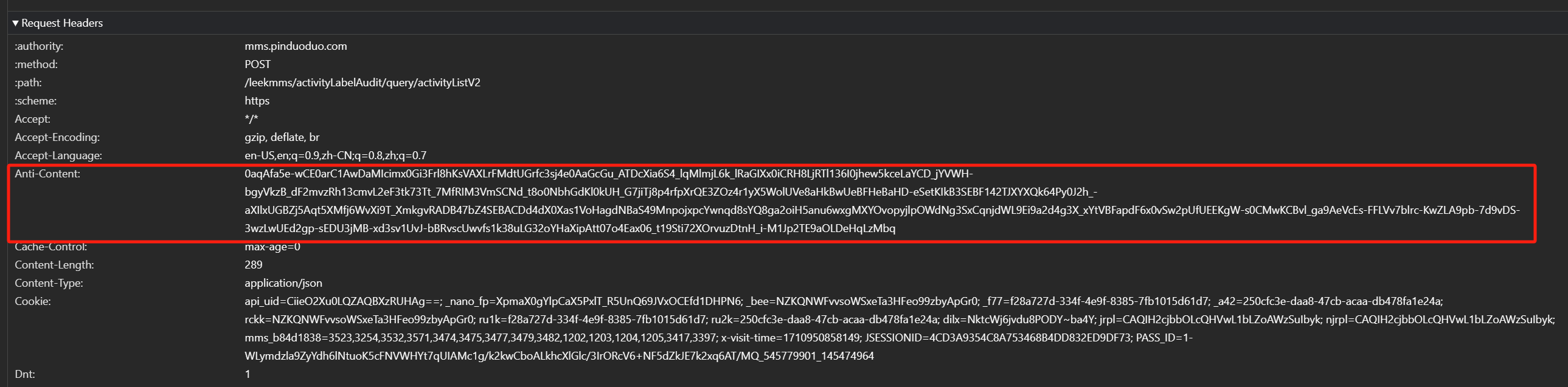
除了这个 Anti-Content 之外,其他所有的认证头信息都非常容易获得,所以此篇博客都是围绕这个东西开始叙述思路,因为其他的请求信息不需要教,你也可以轻松获得。
废话不多说,开始进入 spy 环节,经常逆向 API 的同学肯定非常清楚第一步当然是点开调用链开始我们的奇幻之旅。
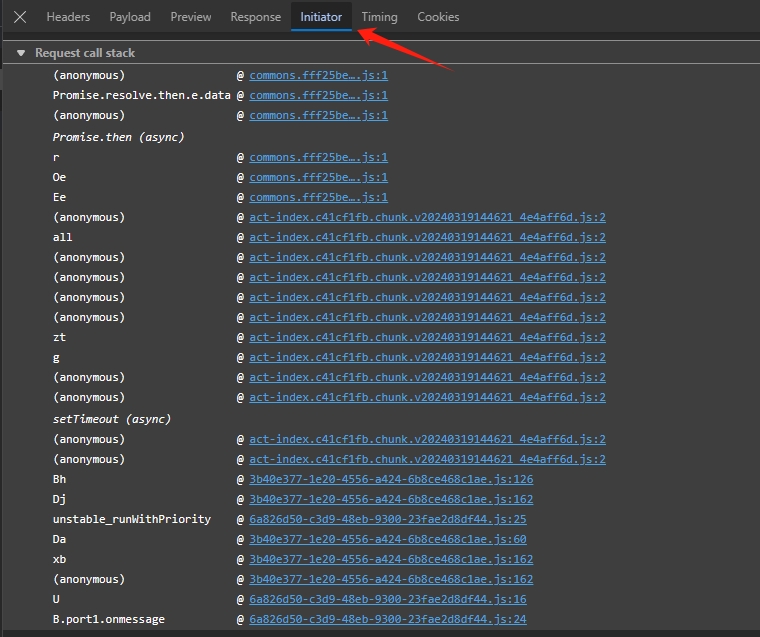
可以看到这个请求经过了四个不同的 JS 文件,最终完成了这个请求。
使用过 react,vue 或者 angular 开发并且使用 webpack 打包过的同学肯定知道, **chunk**和文件名为 GUID 的这两种 JS 文件,一般都是 node*modules 的模块打包,不包含业务代码,基本都是一些第三方库和框架代码,所以我们只需要从 commons.*.js 这文件下手

点开调用链第一次经过 commons.*.js 的地方,开发者工具帮我们自动定位到这个片段。
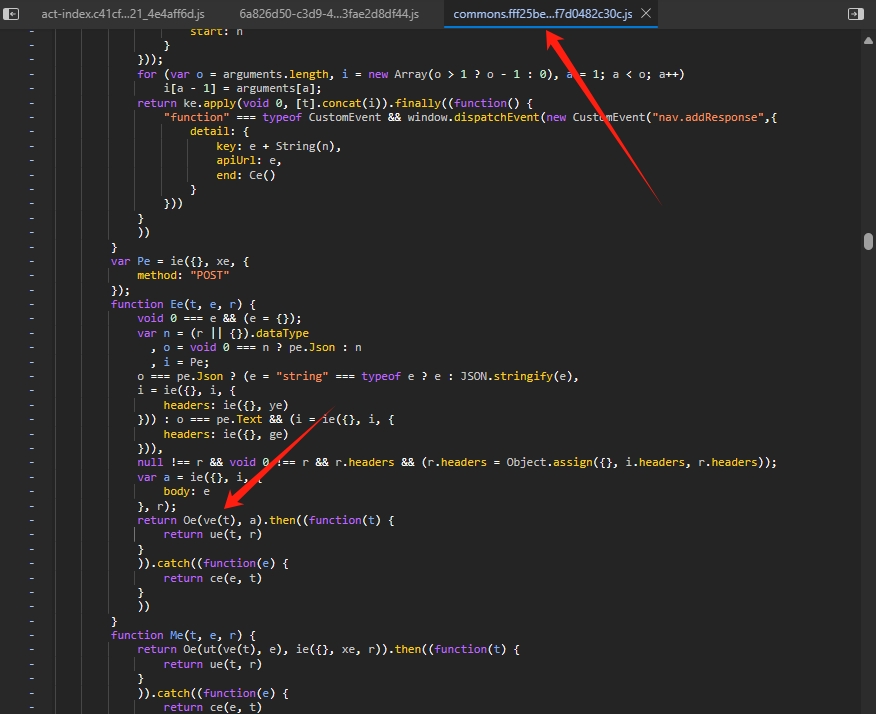
不要犹豫,打上断点,然后刷新页面重新请求一下。
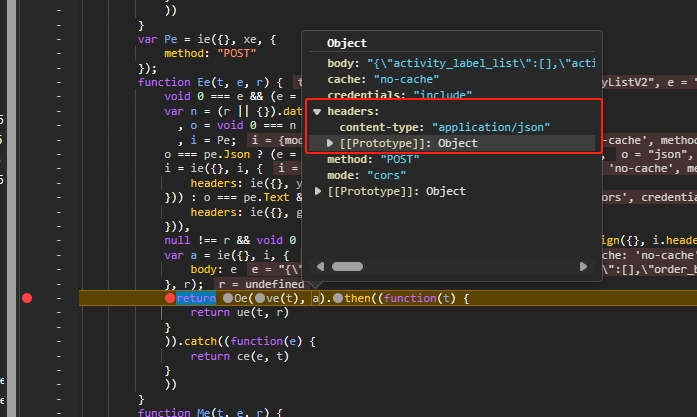
可以看到此时 request headers 还没有附加 Anti-Content ,继续调用链往上找。
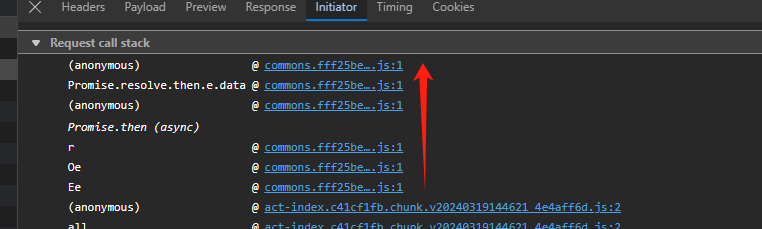
使用同样的方法点开第二个调用链经过的地方,并且打上断点。
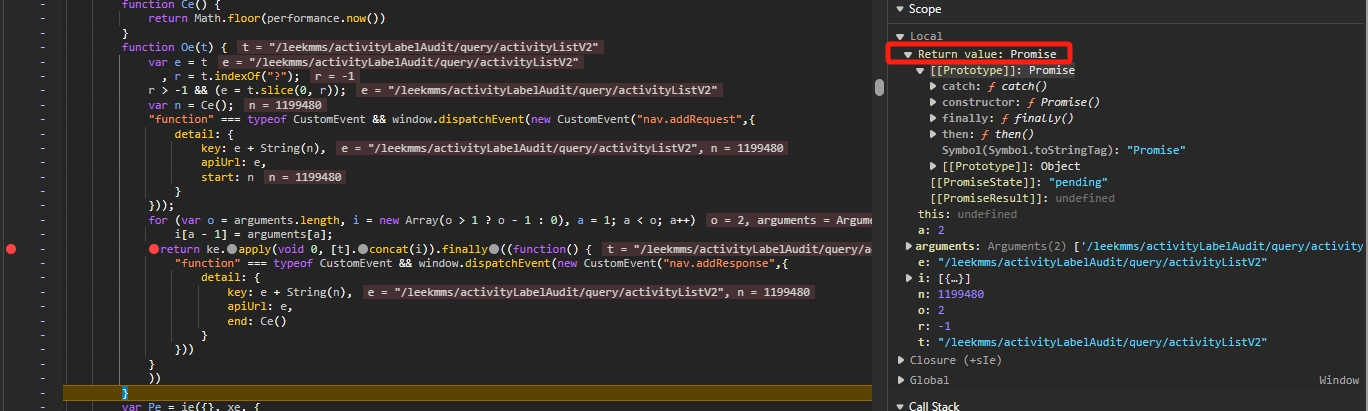
可以看到返回了一个 Promise,因为 Promise 是一个异步语法糖,所以这里没啥用,继续按照相同的办法往调用顶上走,使用老套路打上断点,一直重复这个动作,最后发现。
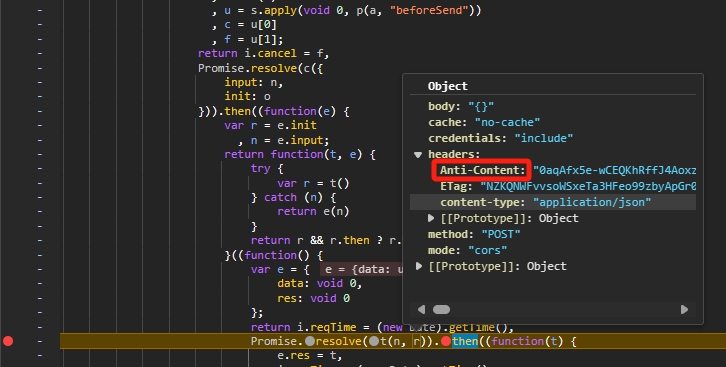
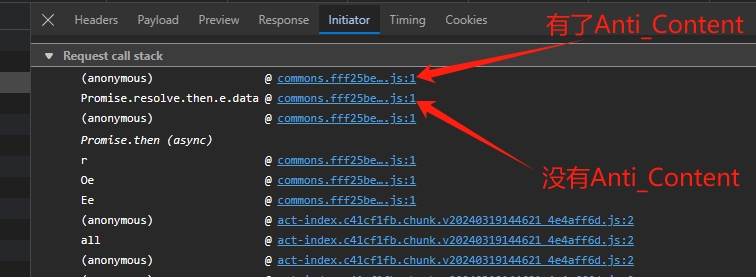
是这里产生了 Anti_Content,那就很简单了,我们把产生的中间段代码跟踪一下就知道是怎么产生的,然后就是漫长的阅读和 Debugging 时间,做过 API 逆向的同学肯定知道,这个过程非常痛苦,轻则十几分钟出结果,重则几天没有结果,因为 JS 打包后的文件非常变态,变量名全是 a,b,c,d 之类的,并且为了兼容浏览器版本,JavaScript 全部都是 es moudule(是的,就是你经常 F12 看到的那一堆和乱码一样的代码),但是还好,只是 1 个小时左右就找到了,这里非常考验你的经验,熟练的同学会非常快,具体过程就不多说了,此篇博客只提供思路。
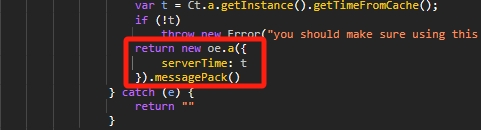
这里产生了这个 Anti_Content,我们可以测试一下,打开浏览器 Console,然后输入这个函数。

非常好,检验没问题,那接下来就非常考验你对于 web 开发的专业知识掌握和底层的理解,你此时要考虑这几个问题:
- 1.如何提取 webpack 打包的代码片段。
- 2.如何提取 ”提取到的 webpack 代码片段” 中的这段函数。
- 3.如何在任何编程语言中运行这段函数?(因为你可能使用任何语言编写爬虫和自动化软件)
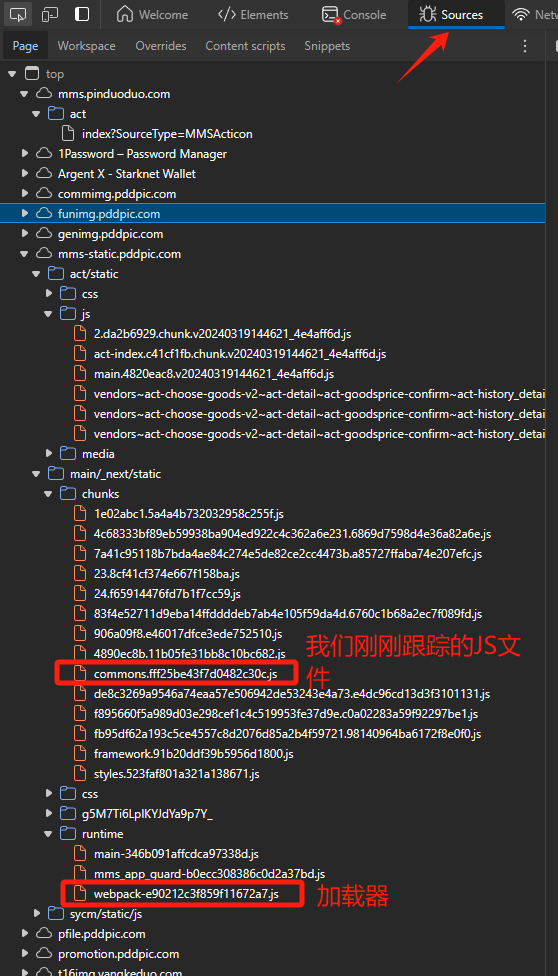
我们开始一步步攻克,首先你要知道 webpack 是什么,以及 babel 是如何把代码编译成浏览器所兼容的 JS,所以你的第一步就是把打包后的代码通过 babel 还原成打包前的,你需要知道 webpack 打包的 JS 脚本会分为加载器和执行器(执行器就是刚刚我们一直跟踪的那个 JS 文件),通常加载器和执行器是一对多的。
然后你需要用 nodejs 写一个这样的 ast 还原代码,大概长这样(不提供源码,只提供思路)。
1 | import * as parser from "@babel/parser"; |
将此转化器保存为 reverseAst.ts(个人习惯,倾向于使用 Typescript),然后使用 tsc 编译成 reverseAst.js,然后把 webpack 的加载器和我们跟踪的 JS 文件从拼多多服务器上下载下来,然后使用我们写的这个脚本开始提取,这样就可以提取 webpack 打包的代码了。

成功输出 prot.js 文件。
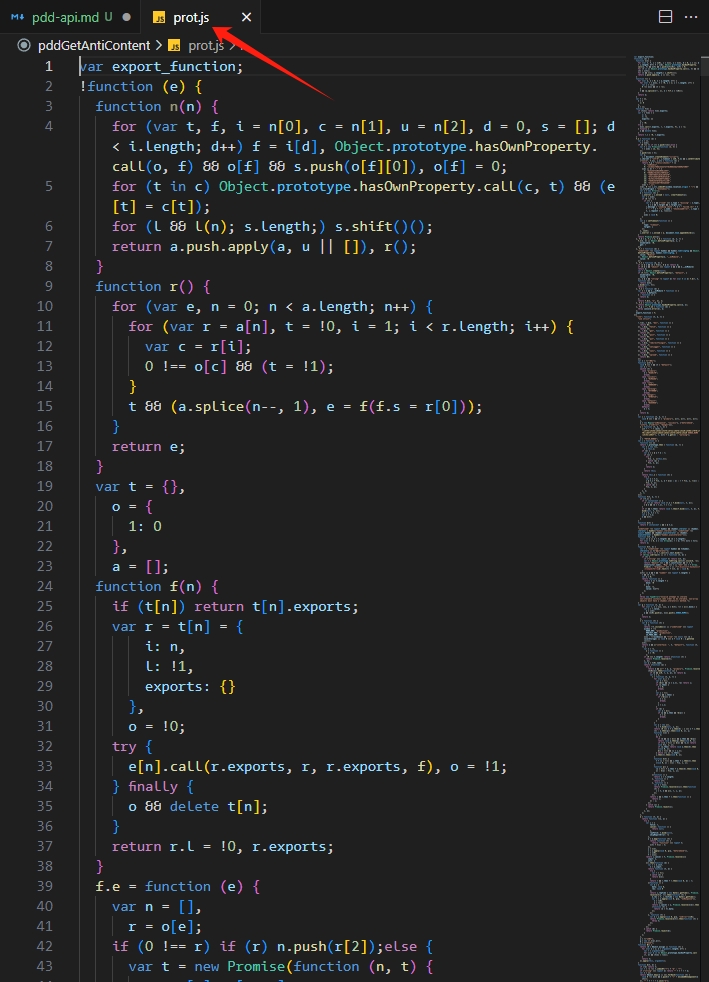
然后回到第二个问题,怎么提取那个产生 Anti_Content 的函数片段,答案就是无解,只能自己一行行看。
在 prot.js 中向上查找,找 oe 是怎么来的,a 方法是怎么来的,这里就不细说了,只能靠你自己悟了。
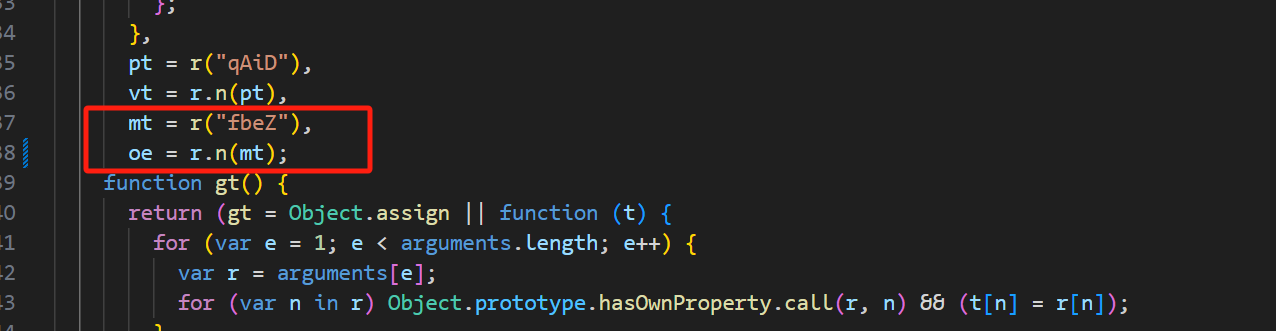
可以看到 oe 是 r.n(mt) 来的,然后 mt 又是 r(“fbeZ”) 来的,先找到 fbeZ,如图:
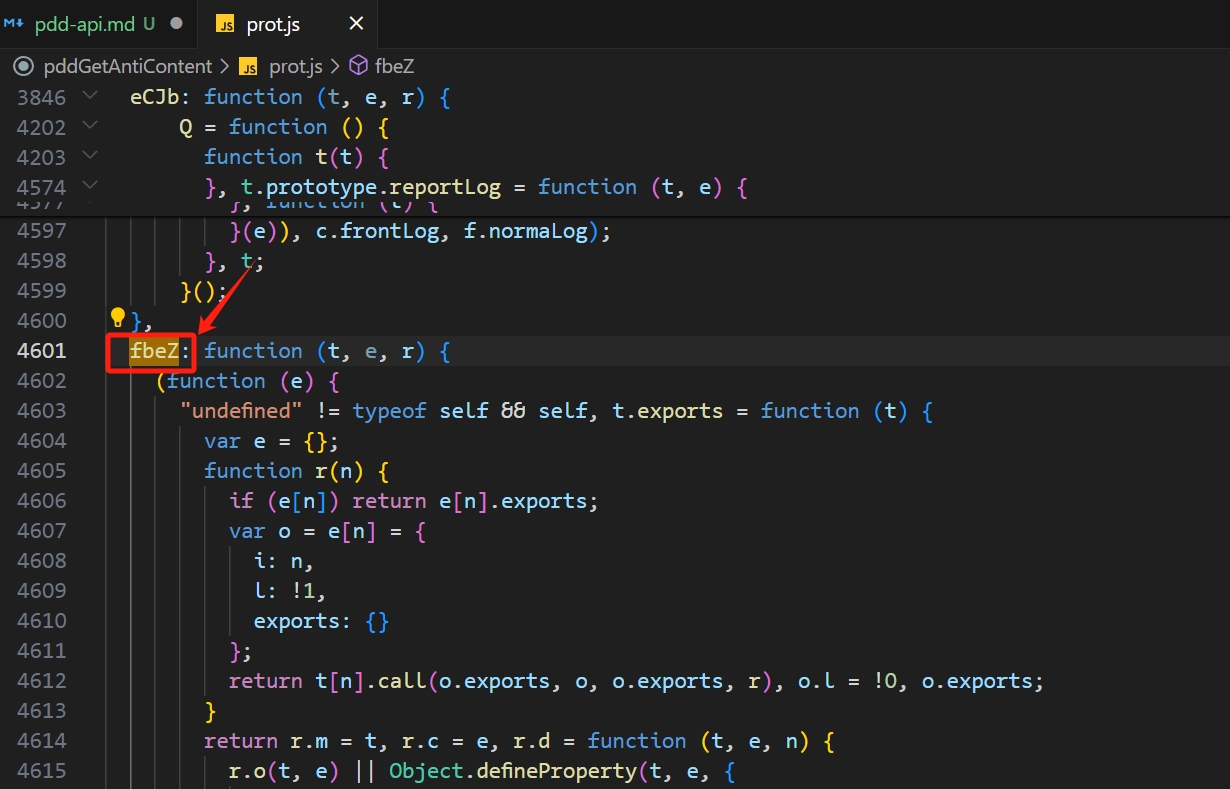
一行行找到以后,你就可以编写自己的自己的代码了,当然你还需要补全浏览器环境才行(不提供源码,只提供思路)。
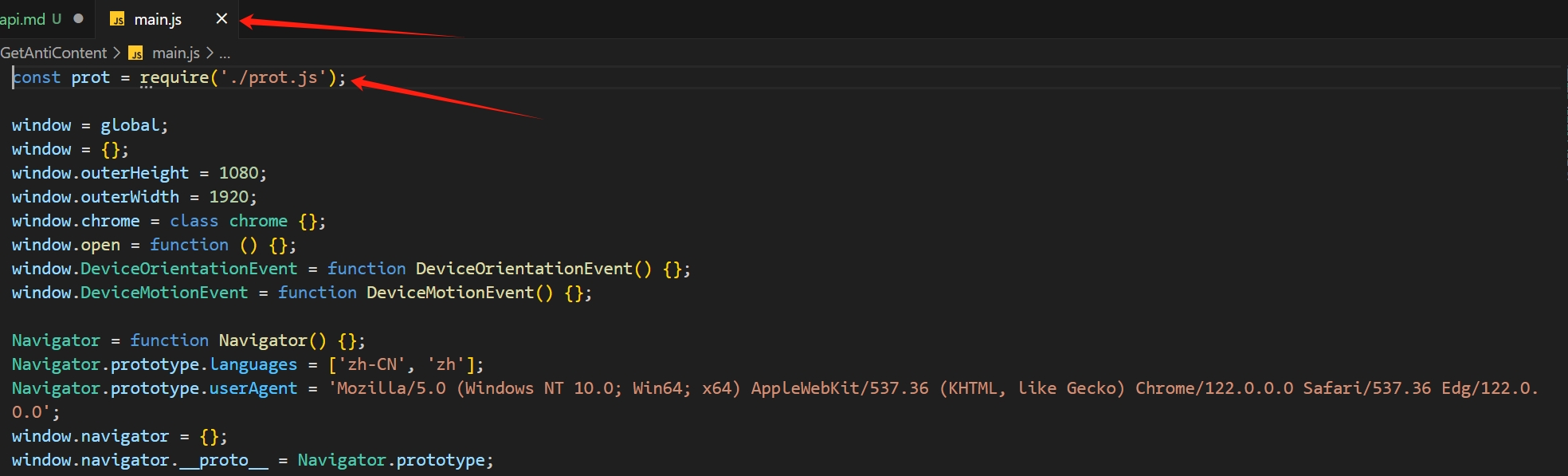
然后编写代码片段。
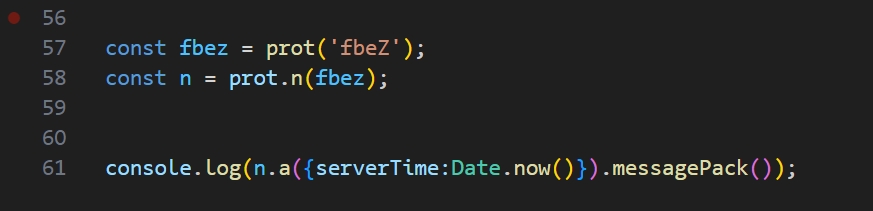
最后执行,大功告成。

然后附加到 postman 请求一下。

请求成功响应,没有附加 Anti_Content 的请求是无法通过拼多多服务器的校验的,会返回 Error。